
レガシー社内システムをGAE/Goでリプレースした軌跡
サイバーエージェントのゲーム・エンターテイメント事業部(SGE)に所属する株式会社QualiArtsでバックエンドエンジニアをしている鈴木光です。本記事はQualiArtsの定期ブログ「QualiArts Tech Note」第10弾の記事となります。QualiArtsでは会社で使われている様々な技術の知見をブログで紹介しています。興味のある方は、QualiArtsとタグの付いている他の記事もチェックしてみてください。
QualiArts Tech Note
はじめに
QualiArtsではバックオフィスが行う資産管理に内製のWebアプリケーションを用いています。ここで資産と表現しているのはPC、備品、検証端末、各種ライセンスのようなものです。今回、サイバーエージェントの全社システム本部からの要請で、PCの資産データを全社システム本部が管理するシステムへ連携する必要が出てきました。これまでサイバーエージェントでは基本的に各子会社が個々に資産管理を行っており、全社システム本部から見るとどのようなPCがどれくらいの期間使われているかなどが不透明であったため、これを改善しコスト削減を狙いつつ、古いPCやOSを使うことによるリスクの管理、データの源泉を一元化することによるシステム精度の向上を行おうという取り組みです。
また社内システムあるあるだと思うのですが、従来の資産管理システム(以降V1と呼称します)は、エンジニアによる保守を受けられていませんでした。従ってバグが放置されたままであったり、技術が老朽化しつつあったり、追加機能が欲しくても実装されなかったりとV1の保守運用の範囲で上記データ連携の対応を行うのは難しいと判断し、システムリプレースを目的とした資産管理システムV2の開発を行うこととなりました。ちなみにV1、V2のダッシュボード画像はこちらになります。
V1のダッシュボード
V2のダッシュボード
技術選定
V1、V2のシステム仕様としては以下のようなものになります。
V1のシステム仕様
- Webフロント:React.js(JavaScript)
- サーバアプリケーション:Spring Boot(Java)、MySQL
- インフラ:プライベートクラウド
V2のシステム仕様
- Webフロント:Nuxt.js(JavaScript)
- サーバアプリケーション:Echo(Go)、MySQL
- インフラ:Google Cloud Platform
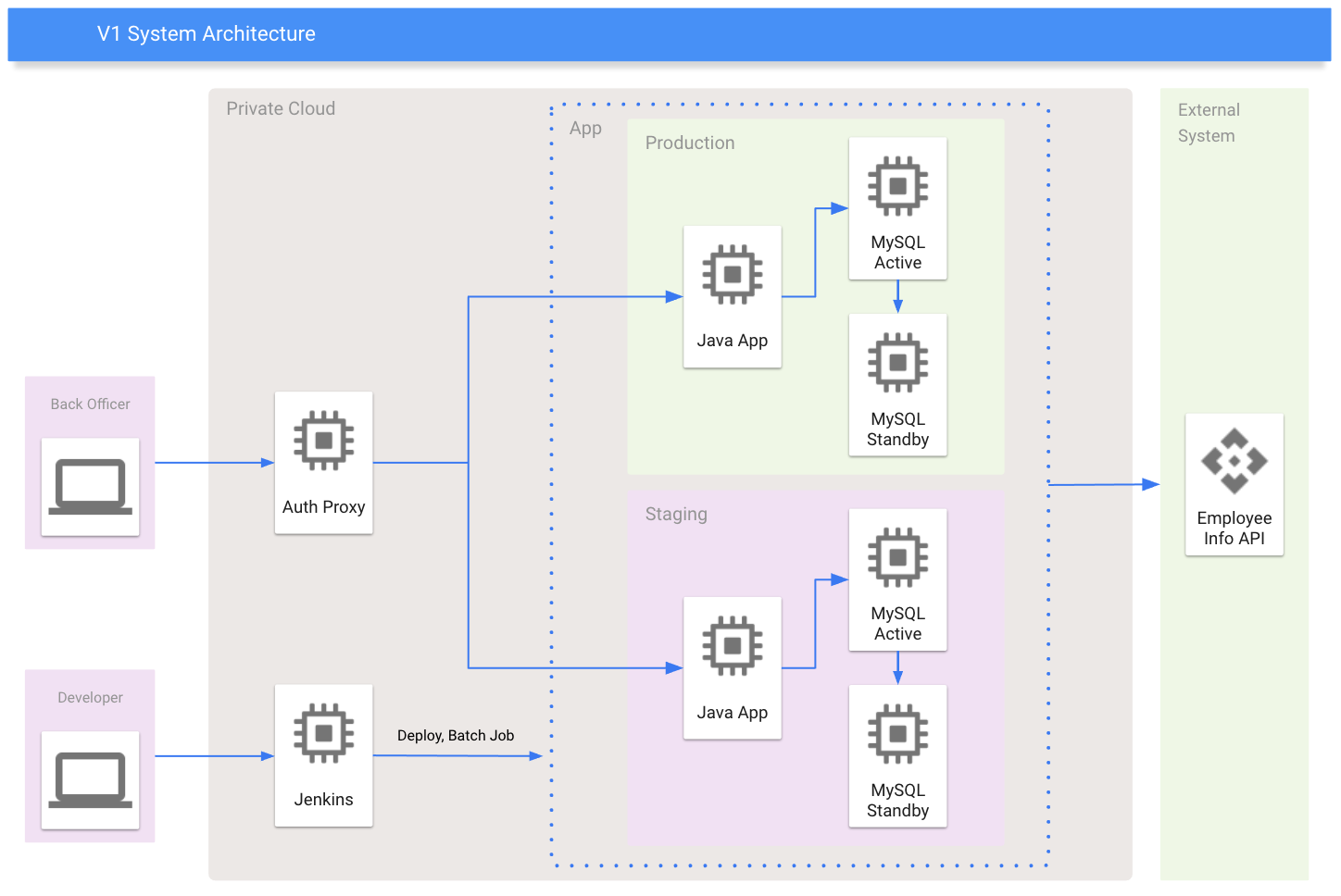
V1はプライベートクラウド上にサーバアプリケーション用のVMとDB用のVMが構築され、それぞれ手動でミドルウェアがインストールされており、更に別のVMに構築されたJenkinsからデプロイを行っていました。
V2について、Webフロントに関しては担当のWebフロントエンジニアが技術選定を行いました。サーバアプリケーションとインフラ構成については私が自由に行って良いとのことだったので、QualiArts社内で今後も保守できそうな技術選定を行ったところ上記のような形に収まっています。技術選定の理由としては、私が経験済みで高速に開発ができる言語であること、社内の流れとしてJavaからGoへの潮流があること、QualiArtsで最近利用しているGoogle Cloud Platformへ移行したかったことなどがあげられます。
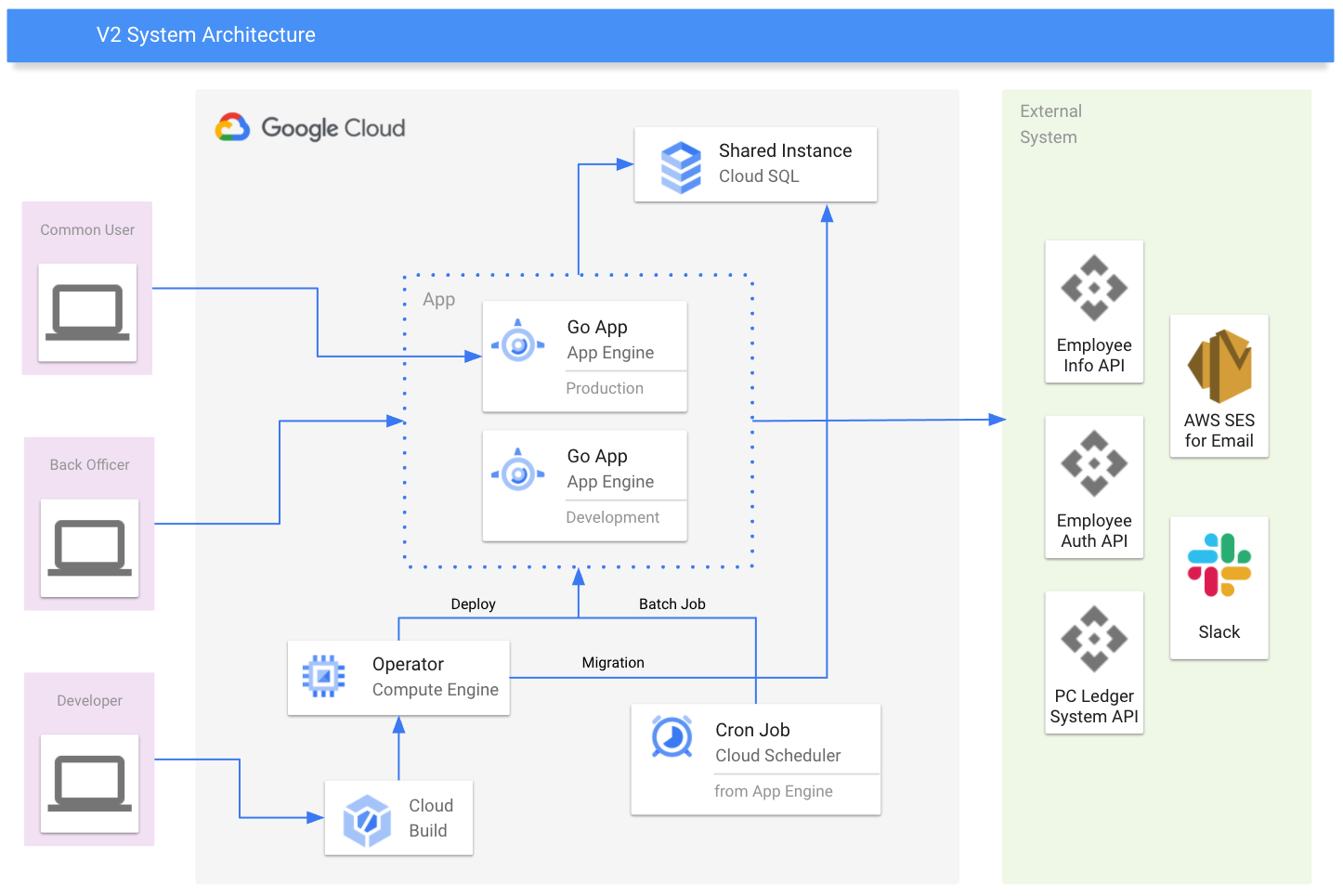
こちらの図がV1とV2のシステムアーキテクチャとなります。
開発の段階
第一段階:システム仕様の把握
現行システムの仕様把握のために最初はコードリーディングから始まりました。インフラに関する仕様書は存在したのですがアプリケーションの仕様書については存在しなかったため、サーバアプリケーションのコードを読んだり、ER図を逆生成したり、実際に触ったりしてシステムの仕様を把握しました。既存のインフラ構成には開発用の環境がなかったため、一時的にGCP上へ本番システムのコピーを作成することでどれだけ触っても問題ない環境を構築しました。
第二段階:データ移行可能な設計とアプリの実装
当然ですが、システムをリプレースするからといってデータを全て吹き飛ばすわけにはいきません。既存のデータを維持しつつ、新しいDBスキーマに移行する必要があります。V1の設計はかなりアプリケーションに寄った設計で、ほとんど正規化もされていませんでした。正規化によるメリット、デメリットはあると思うのですが、今回のシステムは保守のしやすさ > アプリケーションのパフォーマンスであると考え、正規化されたDBスキーマをほぼいちから設計し、そこへ既存データを移行するということを行いました。使われていない不要なカラムの抽出、重複した状態管理値の統合、定義されていないEnum値の把握など、移行可能なDBスキーマを作ることにはとても苦労しましたがなんとか設計を行うことが出来ました。
また、これと並行してアプリケーションの実装も行っています。Goで実装したAPIをSwaggerを用いてAPI定義書として提供し、Webフロントの実装を行ってもらいました。初期設計はしたものの、半分以上は同等の機能を開発するとともに設計を行っていたため、機能単位で設計&実装を実施しました。
第三段階:データ&システム移行の実施
三ヶ月ほどかけて既存システムのリプレースを行うことが出来ました。V2へのシステム移行自体はそこまで難易度が高いわけではなく、出来上がった機能から何度もテストを行い既存機能を実装できているか確認を取りました。また、データ移行に関してはV1のDBスキーマをパースしてV2のDBスキーマへ投入するというスクリプトを実装し、データを投入しては確認するという作業をイテレーションすることで完了しています。この際に冒頭でお話したPCの資産データを全社システム本部へ連携するという処理も行っています。これ以降発生するPCの在庫の追加や貸し出しなどの情報は、システムへその情報が追加されるたびに都度リアルタイムで全社システム本部へ連携するようV2を実装しました。
第四段階:V2の運用開始と追加要件の実装
データ移行が終わるとV2の運用が開始されました。しかし、今回のリプレースはこれで終わりではなく、既存システムに対して追加要件があったためここからはその実装に入ります。具体的には棚卸し機能やワークフロー機能の実装とのことだったので、今まで完全に管理者向けのシステムだったのがユーザー(PCなどを利用する社員)に公開されるシステムへと進化することになりました。
第五段階:V2のユーザー公開と開発の終了
追加機能を二ヶ月ほどかけて実装し、V2のユーザー向け機能が公開されることになりました。公開前後でいくつかのバグが発見されて対応を迫られたものの、特に大きな問題はなく運用できています。
Go
ここからは利用した技術についてお話させていただきます。今回サーバアプリケーションの実装に利用したGoはここ数年非常に勢いのあるプログラミング言語です。Googleが開発を行い、特にインフラやコンテナ関連技術に多く用いられています。ここでは実装に際して工夫した点などを紹介していきます。
ローカル環境
起動速度やデバッガの使いやすさもあったのでローカルにGoをインストールしてはいましたが、別のエンジニアが保守することも考えて開発に使うコマンドは全てコンテナ上で実行出来るようにしています。これはV1が仮想化されておらず環境構築に苦労したという反省からでもありました。また、V2ではGitHub ActionsでCIを行っているのですが、コンテナ化を行ったことによりかなりの部分がそのまま使えるようになってCIの構築が効率化されたり、同一環境上での実行による高い結果の整合性が得られたりしています。例えばこちらのLintチェックするMakeコマンドはdocker-compose上で実行しています。
define docker-compose
docker-compose \
$1
endef
.PHONY: run-lint
run-lint:
# Lintチェック
$(call docker-compose, run --rm golangci-lint golangci-lint run cmd/... pkg/...)Enum
GoにはEnumが存在しません。また、しばしばEnumの値をクライアントと共有したいことがあります。ここで独自のJSON形式で定義されたenumを記述し、サーバではこの定義を元にGoの定数を生成するスクリプトを実装しました。Webフロントで利用しているJavaScriptはJSONを解釈することが可能なので直接利用してもらっています。また、命名規則を定めることでリクエスト時にEnum値の検証を動的に行っています。
独自のスキーマで定義されたEnumを記述するJSON
{
"EquipmentStatus": {
"Kasidasi": "貸出",
"Zaiko": "在庫",
"Zyoto": "譲渡",
"Humei": "不明",
"Haiki": "廃棄",
"Kosyo": "故障"
}
}package enum
import (
"github.com/scylladb/go-set/strset"
)
type EquipmentStatus string
const (
EquipmentStatus_Haiki EquipmentStatus = "廃棄"
EquipmentStatus_Humei EquipmentStatus = "不明"
EquipmentStatus_Kasidasi EquipmentStatus = "貸出"
EquipmentStatus_Kosyo EquipmentStatus = "故障"
EquipmentStatus_Zaiko EquipmentStatus = "在庫"
EquipmentStatus_Zyoto EquipmentStatus = "譲渡"
)
var setEquipmentStatus = strset.New(
EquipmentStatus_Haiki,
EquipmentStatus_Humei,
EquipmentStatus_Kasidasi,
EquipmentStatus_Kosyo,
EquipmentStatus_Zaiko,
EquipmentStatus_Zyoto,
)
func HasValueOfEquipmentStatus(value EquipmentStatus) bool {
return setEquipmentStatus.Has(value)
}
func ListValueOfEquipmentStatus() []string {
return setEquipmentStatus.List()
}ここで特徴的なのは、Enum名を日本語(訓令式)で定義していることとEnumの値を数値ではなく文字列にしていることです。既存実装を把握する際にそれぞれのEnumが何を表しているのか把握しづらく、また値から逆引きしたいときも一手間必要でした。このようにすることでEnumが表現していることを直感的に把握しやすく、また逆引きしたい場合でも把握しやすいというメリットが生まれます。パフォーマンスやストレージ容量をあまり考慮しなくて良いのであれば、この手法は割とアリではないかと個人的には考えています。
そしてこちらが不正なEnum値をリクエストした場合にエラーとなる様子です。リクエストボディのJSONをパースし、`e_`接頭辞から始まるプロパティ名を再帰的に探索、その値がEnum定義に存在するかどうかをチェックするというコードを`echo.MiddlewareFunc`、つまり全リクエストが通る処理として実装しています。

go-swagger
多くの場合、APIサーバを提供する際は何かしらの定義書を作る必要があります。本システムでは定義書を元にサーバを実装するのではなく、サーバ実装から定義書を生成する手法を取りました。Goにはアノテーション(アトリビュート、デコレータなど)に相当する機能がないため、コメント文やstructタグにその情報を埋め込むことでSwagger Specを生成できるようにしたライブラリがあります。今の所go-swagger/go-swaggerとswaggo/swagの二種類がメジャーなライブラリとして公開されており、色々検討した結果 go-swagger/go-swaggerを採用しました。比較としてはこちらの記事が参考になるためぜひご覧ください。
マスターデータAPI
マスターデータのCRUD操作は典型的な操作です。マスターデータに変更が加わるたびにこのAPIを手動で修正するのは煩雑な作業となるため、この部分も自動生成を行うことでマスターデータのテーブル構造が変化してもCRUD APIとしてはコマンド一発で対応する事ができるようになりました。また、CRUD APIのスキーマを記述しているSwagger SpecはGit管理されているためテーブル構造の変更差分をWebフロントエンジニアが確認しやすい状態になっています。Swagger Specの自動生成とGit管理についてはQualiArts Advent Calendar 2020の記事として私が執筆したこちらの記事に関連情報が記載してあるので気になった方はご覧ください。
その他ライブラリなど
-
-GoのORMとしてはGORMやxormが有名だと思いますが、今回はSQLBoilerを採用しました。
-SQLBoilerはDBファーストに設計されており、既存DBからGoコードを自動生成することでクエリを型安全に記述できるため、書き心地がとても良いです。
-
-Goでモックといえばgolang/mockなのですが、エラーのわかりやすさという観点から個人的にはこちらがおすすめです。
-少々偏っている気がしますが、こちらの比較記事がわかりやすいです。
-
-DIライブラリです。google/wireも検討しましたが、こちらのほうが手軽で学習コストが低いと感じたので採用しました。
- -こちらはライブラリというよりGo製のマイグレーションツールです。私は数年前から使っており、他のツールにはない機能や使いやすさもあっておすすめです。
Google Cloud Platform
QualiArtsではメインで利用するクラウドプロバイダーとしてGCPを採用しています。今回のV2でも採用したため利用するにあたって工夫した点などを紹介していきます。
Google App Engine
サーバアプリケーションを実行する環境としてGoogle App Engineを採用しています。GCPにはGCE、GKEやCloud Runなどの実行環境がありますが、今回は可能な限り運用コストを下げたかったのでDockerfileすら不要なGAEを採用しています。また、個人的な目標としてゼロスケール(利用されていないときはインスタンスが0台になる)が可能なインフラを構築したかったためGAEは最適でした。実際、コールドスタートしても数秒もかからずにインスタンスが起動してレスポンスを返してくれます。コールドスタートからの起動時間の指標としては3秒以内に返せるかというのがありました。これはSlackのコールバックの時間制限です。V2ではワークフロー機能の一つとして、ユーザーからPCや備品などの申請が行われた際に、その人の上長のような承認ユーザーへSlackメッセージを送信し、承認ユーザーはSlackのモーダル上から承認ボタンを押して次のフローに進むという機能があるのですが、この承認ボタンを押される時に必ずインスタンスが稼働しているとは限らないので出来ればSlackのコールバック時間制限である3秒以内にレスポンスを返してほしかったというものです。こちらは問題なく動作していて実際は3秒もかかっておらず、体感ですが1秒程度で返してくれています。また、最悪3秒以内に返せなくてもSlack上でリトライの表示が出るため必須要件ではなかったというのもあります。
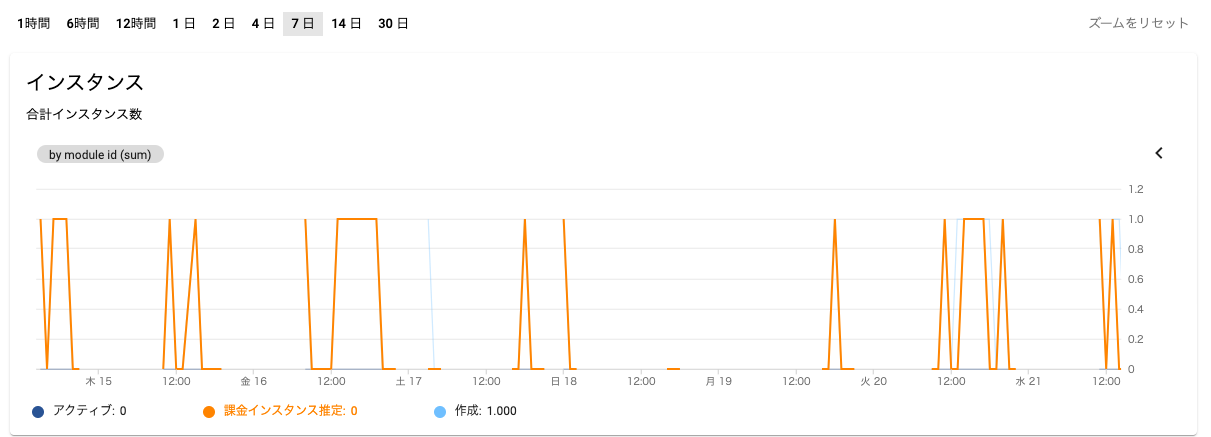
ちなみにこちらの画像が課金インスタンスの稼働状況です。このような社内システムは業務時間外にアクセスされることはあまりないため、土日や深夜のような時間は課金が発生せず運用コストの削減にも繋がっています。あまり作業がない午前中や、そもそも利用していない時間帯にも課金インスタンスが稼働していないこともわかります。
Cloud Build
前述の通り、単体テストやLintチェックなどのCIはGitHub Actionsを用いているのですが、デプロイについてはCloud Buildを利用しています。それまではJenkinsを用いてデプロイやDBのバックアップ、バッチ処理などを行っていたため、運用コストの削減になりました。
Cloud SQL
V1ではプライベートクラウド上にある二台のVMへそれぞれ本番とステージング用のMySQLをインストールして運用していました。これをGCPに載せ替えるということで、RDBのマネージドサービスであるCloud SQLを利用しています。また諸々の都合上、環境としては本番環境と開発環境の二つになっているのですが、そこまで可用性が求められるわけではないため、それぞれのCloud SQLインスタンスを建てるのではなく一つのCloud SQLインスタンスに二つの環境のDBを置くことで管理コスト、価格コストを抑えています。さらにV1時代ではJenkinsサーバを建ててDBバックアップを取っていたのですが、Cloud SQLには自動バックアップ機能が存在するため、これを有効にするだけで毎日自動でバックアップを取って一週間保存してくれるので大変重宝しています。このバックアップ機能は手動でトリガーすることも可能で、何かバッチ処理を実行する前や修正パッチ用のクエリを流す前などに実行しています。
その他工夫した点
GAEへデプロイする際の環境変数の設定について
開発環境はdocker-composeで管理しているため、アプリケーションを利用する際は`.env`ファイルから環境変数を読み込んでいます。しかし、GAEはapp.yaml上に環境変数を直接設定しないといけません。これらの設定ファイルを二重で管理したくないため、デプロイ時に`.env`を読み込んでapp-secret.yamlを生成し、app.yamlからこのファイルをincludeするという手法をとることで環境変数を`.env`ファイルで一元管理することにしました。
GAEへのデプロイ方法について
前述したとおりデプロイにはCloud Buildを利用しています。理想としてはCloud BuildからGAEへデプロイ出来ればよかったのですが、ドキュメントの「App Engine スタンダード環境使用時のタイムアウト エラー」にある通りGAEのスタンダード環境を利用しているとCloud Buildから直接デプロイすることは出来ません。GAEのFlex環境やCloud RunではCloud Buildからデプロイができるのですが、Flex環境ではゼロスケールが出来ないこと、Cloud RunではDockerfileやコンテナイメージの管理が必要だったことから断念しました。結果としてはオペレーション用の小さなVMを立ててそこからデプロイするという方法で対応しています。Cloud BuildのデプロイタスクではこのVMに接続し、VM内でデプロイのコマンドを叩くという流れです。サーバレスにするためにサーバを建てるという少し本末転倒な状態にはなってしまいましたが、別件としてCloud BuildからDBマイグレーションを行おうとすると少々面倒でVM内からDBマイグレーションを行うと楽になるということもあり結果的にはこの手法で良かったかなと思っています。
cronジョブについて
システムの仕様上、定期的にいくつかのバッチ処理を行わないといけないというものがあって専用のコマンドをspf13/cobraで実装していたのですが、AppEngineのcronジョブではコマンドを実行できず、HTTPのエンドポイントを用意してCloud Schedulerからそれを叩くという方法を利用することになっています。既にコマンドとして実装しており、全く同じ挙動をするエンドポイントを提供するとなるとコマンドを1つ追加するたびに二つ管理しないといけません。そこで単一のHTTPエンドポイントを用意し、処理内で`cobra.Command`構造体を生成してクエリパラメータでコマンドを指定し実行するという方法をとることでコマンドに一元管理することができました。ちなみにこちらがそのサンプルコードとなります。
e.GET("/cron", func(c echo.Context) error {
req := c.Request()
// AppEngine以外からのアクセスは弾く
if req.Header.Get("X-Appengine-Cron") != "true" {
return errors.New("不正なアクセスです")
}
// リクエストごとにコマンドを作らないと2回目以降のコマンド実行で`context canceled`になる
rootCommand := &cobra.Command{}
args := req.URL.Query().Get("args")
// args=foo,barの形式で引数を渡す
rootCommand.SetArgs(strings.Split(args, ","))
return rootCommand.ExecuteContext(req.Context())
})おわりに
このシステムは基本的にバックオフィスチームが日常的に使うものですが、先日V2稼働から初の棚卸しがあり、ユーザー側からも便利になったとの声が多く聞こえてきてとても嬉しく思いました。今までは各棚卸し製品ごとにスプレッドシートが共有され、自分の名前を見つけて更新していくというフローだったのですが、V2にユーザー機能と棚卸し機能が入ったことでシステムへログインして表示される棚卸し対象資産の利用状況を更新するだけ、というフローに変わったためです。また、GAEの採用例としてはWebサービスやゲームなどが多いと思うのですが、社内システムのような稼働時間が24/365ではなく負荷もあまりかからないサービスにも運用コスト、価格コスト的にとてもマッチするので是非参考にしてみてください。

- 鈴木 光(Suzuki Hikaru) 2019年にサイバーエージェントに新卒入社。QualiArtsにて運用プロジェクトのバックエンドエンジニアとして開発に携わり、いくつかのプロジェクトを経験。現在は新規プロジェクトのバックエンドエンジニアとして従事。








