運用4年目のサービスのインフラをGCPへ移設した裏側
こんにちは。グリフォンでインフラエンジニアをしている徳田です。
日々運用しているインフラの改善や新規ゲームのインフラ設計などを行っているのですが、先日、グリフォンで4年運用しているブラウザゲーム「不良遊戯 シャッフル・ザ・カード」(以下、不良遊戯)のインフラをGoogle Cloud Platform(以下、GCP)へ移設しました。今回は、その時の経緯や設計、行った作業やTipsについてご紹介します。
経緯
大まかな経緯として、
- インフラコストの削減
- パフォーマンスの向上
- インフラ環境の整備
- 技術的な挑戦
がありました。しかし、事の発端は私がGCPを使いたい・試してみたいというなんとも自分勝手な提案だったのですが(笑)。
「インフラコストの削減」と「パフォーマンスの向上」については、不良遊戯をリリースしたのが2014年の5月で3年経っており、リリース時に比べVMのコア単価が安く、CPU性能も向上していることからコストパフォーマンスが大きく改善されると考えたためです。
次に「インフラ環境の整備」ですが、既存の環境ではインフラの構成管理がされておらず、設定などは動作しているVMに入って確認する以外に方法がありませんでした。これを改善するために移設に際してコードによるインフラ構成管理を進めることにしました。最後に「技術的な挑戦」ですが、移設前の環境はGCP・AWS・Azureのような最近の時流に乗ったクラウドを使用していませんでした。これらのクラウドが出す様々な新サービスを検証したり、新サービスを利用した機能の実装などを進めていく糧として移設作業を行いました。
また、個人的にもGCPのサービスの理解・習得を目的としていました。この移設作業を当時新卒1年目の私に任せてくださったCTOの川村さんにはとても感謝しています。
設計・行った作業
移設に際して、既存環境の調査からGCPのサービスの検証・利用の検討など色々行ってきました。
Cloud SQLの利用の検討
既存の環境ではデータベースにMySQLを利用していました。GCPではCloud SQLというMySQLのフルマネージドデータベースサービスがあり、このサービスの利用を検討しました。利点としては、
- 構築が簡単
- バックアップ・レプリケーションの設定も容易
- スケールアップ・リードレプリカによるスケールアウトが簡単
と、何をするにも簡単・容易で運用のコストがとても低くなるような魅力的なサービスですが、欠点があり、
- 再起動が必要な更新があった際にMaintenance window, Maintenance timingで指定したタイミングで自動的に再起動がかかる
- ストレージエンジンにInnoDBしか使えない
などがあります。
致命的だったのがストレージエンジンにInnoDBしか使えないというもので、既存の環境ではInnoDBとMyISAMの2つを利用していました。なので、利用するにはMyISAMのテーブルをInnoDBに置き換える必要がありました。この置き換えとテスト作業のコストが大きくなってしまうと考え、今回利用するのは見送りました。また、時期・時間が指定できるとはいえ自動的に再起動がかかるのも許容し難い要件だったと考えています。このため、既存の環境と同様に通常のVMでMySQLのHA構成を構築することになりました。
OS・ミドルウェアのバージョンアップ
実は移設とは名ばかりで、タイトルの通りVMの中身は一新されています(笑)
既存ではCentOS6を使用していましたが、移設後の環境ではCentOS7を利用するようにしました。また、PHPの実行をapache+mod_phpで行っていましたが、php-fpmに置き換え、PHPのバージョンも5.5から5.6にアップデートしました。PHP7の利用も検討したのですが、アプリ側の実装・テストの工数が膨大になってしまうためPHP7へのアップデートは断念しました。
その他ツールやミドルウェアも全て最新のものにバージョンアップを行いました。
コードによるインフラ構成管理(Infrastructure as Code)
既存の環境では構成管理がされておらず、特定のVMの設定については動作しているものが正しい、という状態になっていました。これを改善するために以下3つのツールでコードによる構成管理を行うようにしました。
Terraform
Terraformは設定ファイルを用いてインフラを構築・変更できるツールです。設定ファイルをgitリポジトリで管理して構成管理をしています。今回インフラの構成管理をするに当たってTerraformの役割は以下のとおりです。
- インスタンスの作成
- インスタンスグループのスケール設定
- ネットワークの作成と設定
- ロードバランサーの作成
- DNSレコードの設定
- GCSのバケット作成
- GCPアカウントの管理
インスタンスの作成ではVMの中の設定は行わず、あくまでも指定のイメージでインスタンスを立ち上げるところまでを行っています。
Ansible
Ansibleは構成管理ツールです。そのままですが、管理する対象がAnsibleで対応していれば構成の管理ができます。対応していなくてもmoduleを実装すれば・・・。その辺は置いておいて、今回Ansibleに任せる役割は各VMの構成管理です。
「管理する対象がAnsibleで対応していれば」とありますが、AnsibleでGCPのインフラを管理することもある程度は可能です。しかし、問題点がいくつかあり、
- 対応しているモジュールの数が少ない
- gceモジュールなどのいくつかのモジュールでapache-libcloudというライブラリを使用している
というものがあります。2つ目にあるapache-libcloudというライブラリは、複数のクラウドを共通したインターフェースで操作ができるというものです。このライブラリ自体は便利なもののように思えますが、設定する際に共通のインターフェースになっているため各クラウド特有の設定などがしづらいなどの問題があります。また、機能の追加に対してapache-libcloudとAnsibleの2箇所での対応を待たなければならず、最悪Ansibleからの設定ができない状態が続く可能性もあります。
これらからGCPについてのインフラの構成管理はAnsibleではなくTerraformを利用しています。
Packer
Packerはマシンイメージを構築するためのツールです。イメージを作成する際のプロビジョニングツールにはAnsibleを使用しています。
Terraformで、イメージを変数で指定できるようにしておくことで、Packerで取得したイメージの情報をTerraformに渡し、インスタンステンプレートを作成してインスタンスグループに設定する所までTerraformでやってくれるように設定することができます。
メトリクスとログの収集
既存の環境ではメトリクスの収集にMuninを利用しており、ログの収集にはtd-agent(fluentd)を利用してログサーバーにログを集約させていました。移設後の環境では、メトリクスの収集をStackdriver Monitoringに、ログの収集にStackdriver Loggingを利用するようにしました。Stackdriver Monitoringでは、標準で収集されているメトリクスの表示・監視や稼働時間チェックなどができます。また、Stackdriver agentをインストールすることで対応したミドルウェアのメトリクス収集・監視とプロセス監視をすることができます。
Stackdriver LoggingはfluentdをベースとしたLogging agentをインストール、またはfluentdにfluent-plugin-google-cloudプラグインをインストールして利用することができます。APIを直接呼び出して利用することもできます。機能としては、
- クエリを用いたログの検索
- ログのストリーミング表示
- ログ指標の作成
- ログのエクスポート
があります。今回設定したものではアクセスログのログ指標を作成してStackdriver Monitoringでステータスコードの可視化をしたり、ログのエクスポートでGCS(Google Cloud Storage)とBig Queryにエクスポートする設定などを行いました。Big Queryにエクスポートすることで、後にログの分析やGoogle Data Studioと連携させて可視化させたり、その他BIツールと連携させることができます。また、ログのエクスポート機能が強力で、Cloud Pub/SubにもエクスポートできるのでGCPのサービスと非常に連携しやすいです。
Master Nodeの識別方法とFailover処理の置き換え
既存の環境ではheartbeatを用いたVIP運用でMaster Nodeを判別していました。しかし、GCPではVIPの利用が難しい上、VIPの切り替えに1分弱かかってしまいます。具体的にはNICにVIPを割り当てておき、GCPのネットワーキングのルートで送信先がVIPだった場合にネクストホップを指定のインスタンスにするように設定することで実現できます。ただ、この設定自体が非常に面倒なのと、ルート情報の変更に1分弱かかる上にルート情報の反映も1分弱のうちの時間でバラバラに反映されます。。
このようにGCPでのVIPの利用は不向きなため別の手段を考え、consul・consul-template・haproxyの3つのミドルウェアを組み合わせてMaster Nodeの識別する構成を構築しました。
Consul
Consulは大まかには以下の機能を有した分散システムです。
- サービスディスカバリ
- ヘルスチェック
- KVS(Key-Value Store)
サービスディスカバリでクラスタのノード検知、ヘルスチェックでミドルウェアの監視、KVSでMaster NodeのIPアドレスとポート番号を管理しています。
Consul-Template
Consul-TemplateはKVSの値の更新、ノードの検知、サービスの更新などをトリガーにConsulの情報を用いてテンプレートからファイルの出力と任意のコマンドを実行してくれるツールです。今回は、Master NodeのIPアドレスやポートがKVSに格納されるので、その情報を元に後に解説するHAProxyの設定ファイルを出力するように設定しています。また、ファイルの出力後にHAProxyのリロードも行っています。
HAProxy
HAProxyは多機能なプロキシサーバーです。
- プロキシ
- リバースプロキシ
- ノーマライザ
- ロードバランシング
- トラフィック制御
と本当に多機能なのですが、今回ではただのプロキシサーバーとして利用しています。
Master Nodeの識別方法
簡単ではありますが、以下のような関係図になります。
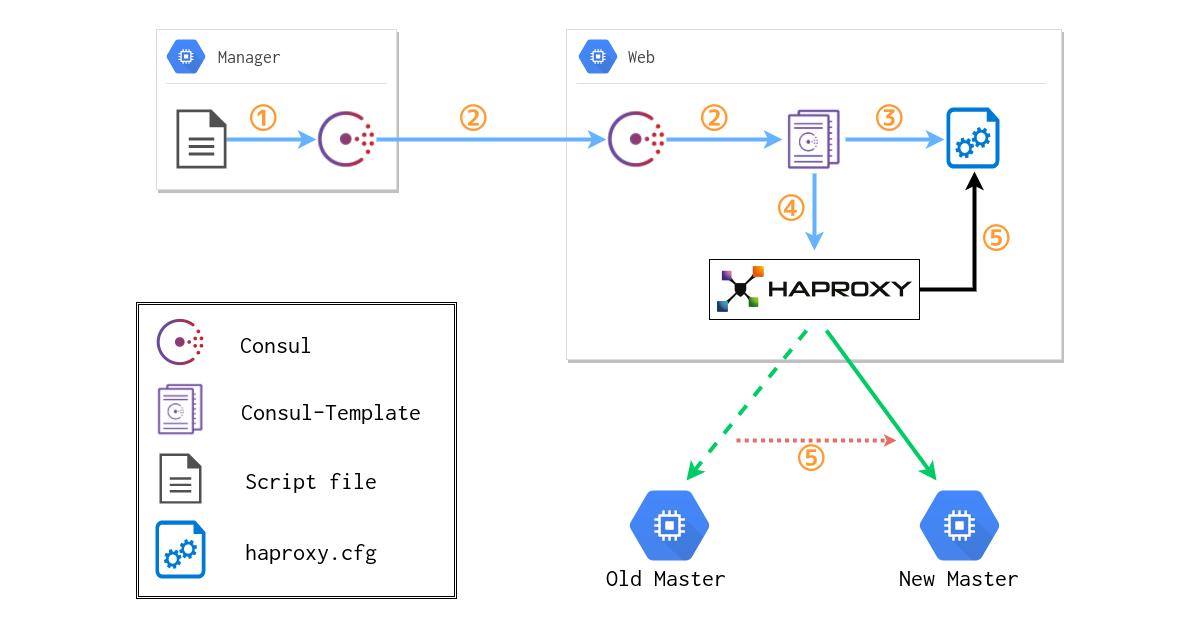
流れとしては、
1. 任意のスクリプトなどからConsulのKVSを書き換える
2. ConsulがKVSの変更を他ノードに伝搬
3. Consul-TemplateがKVSの変更を検知し、テンプレートファイルからHAProxyの設定ファイルを出力
4. Consul-TemplateがHAProxyのリロードを行う
5. HAProxyが設定ファイルを読み込み接続先を変更する
という手順で反映されます。これによって、アプリケーション側はHAProxyが動作しているポートに対して接続すればよい状態となり、VIPと同じような感覚で扱うことができます。切り替えもKVSの書き換えを行ってから即時にHAProxyに設定が反映されます。
欠点としては、VIPと比べてミドルウェアが3つも増えてしまう点でしょうか。学習コストや運用面で監視などを入れる必要があるので少々手間が増えてしまいます。
Redisやデータベースのデータ移行
既存環境からGCPの環境へ移す必要のあるデータとしてRedisのデータとデータベースのデータの2つがありました。Redisのデータ移行についてはbgsaveを実行して生成されるダンプファイルが10GB程度だったのでGCP環境へそのファイルをコピーして展開する形で移行を行いました。データベースのデータ移行については当初既存環境とGCPの環境間でのレプリケーションでデータ移行をする方法も検討していましたが、データベースのダンプ・GCPの環境へコピー・リストアの作業がメンテナンス時間内で収まることが分かり、Redisとほぼ同様の手順で移行を行いました。
Tips
この章では、GCPの環境へ移設する際にあたった問題や便利な機能などを紹介したいと思います。
1.GCPではVIPが使いづらい
「Master Nodeの識別方法とFailover処理の置き換え」にもありますが、GCPではVMに対して割り当てることができるIPにアドレスは1つに制限されています。また、ネットワークのサブネットが/32で設定されており、全てのパケットがゲートウェイに向かって送信されるため、あるVMでNICにVIPを割り当ててもVPCネットワークがそのIPアドレスを知らないのでパケットが破棄されてしまいます。このため、VPCネットワークのルートでルート情報を登録する必要があるのですが、この情報を登録してから反映されるまでに1分ほどかかります。
VIPを使うからには、VIPを付け替えた際には瞬時に切り替わってほしいと思うのですが、それを実現することはGCPでは難しそうです・・・。
2.Stackdriver Monitoringにモニタリングエージェントを使用してカスタムメトリクスを送る
Stackdriver MonitoringのMonitoring Agentはある程度のミドルウェアのメトリクスを収集することができますが、移設後の環境でPHP-FPMを利用しており、これにMonitoring Agentは対応しておりません。なので、カスタムメトリクスを使ってメトリクスを送れるのでは?と考えてドキュメントを漁ったのですがどこにもなく・・・。しかし、Monitoring Agentのソースを読んでいたらカスタムメトリクスを送る方法があったので簡単に紹介しようと思います。
Monitoring Agentはcollectdからフォークされて作成されています。なので、単純にはcollectdのプラグインを作成して、指定のデータ構造でcollectdにデータを返す用に実装することでカスタムメトリクスとして送信されます。また、プラグインを実装できる言語は
などが対応しているようです。
あとは、普通にcollectdのプラグインを実装するのですが、メトリクス値をセットする際にmetadataを付与する必要があります。「stackdriver_metric_type」というKey名で値に「custom.googleapis.com/」で始まるカスタムメトリクス名を入れます。例として、PHP-FPMのリクエスト数を取得するような場合は「custom.googleapis.com/php_fpm_requests」という値を入れるようになります。
このmetadataを付与することでMonitoring Agentがカスタムメトリクスとしてメトリクスを送信するようになります。プラグインの実装方法詳細については今後グリフォンのエンジニアブログで紹介する予定です。グリフォンブログ
3.HTTP(S) ロードバランサーが502を返す
Stackdriver Loggingでレスポンスのログを確認していた時に、所々でステータスコードが502を返しているレスポンスがありました。これの原因を探していた所、以下の記事を見つけました。
[Tuning NGINX behind Google Cloud Platform HTTP(S) Load Balancer]
こちらの記事でnginxでkeepaliveをONにした時、keepalive_timeoutのデフォルト値がGCP HTTP(S) ロードバランサーとの相性が悪いことを示しています。
原因は、nginxのkeepalive_timeoutのデフォルト値がHTTP(S) ロードバランサーのkeepaliveのtimeout時間より短いというものでした。流れとしては、
1. nginxがkeepalive_timeoutの時間でソケットを閉じようとする
2. 同時にHTTP(S) ロードバランサーが新しいリクエストを送る
3. nginxが違反なパケットだと認識してRSTパケットを返す
4. HTTP(S) ロードバランサーはRSTパケットを受け取ってクライアントに502を返す
という流れです。HTTPメソッドで冪等であるメソッドの場合はHTTP(S) ロードバランサーがリトライしてくれるのですが、POSTメソッドのような冪等でないメソッドの場合リトライが発生せず502を返してしまいます。
対策としては、HTTP(S) ロードバランサーのkeepaliveのtimeout時間より長い値をnginxのkeepalive_timeoutにセットすることです。上記の記事の検証結果でHTTP(S) ロードバランサーは10分でタイムアウトしているそうなので600より大きい値をセットすることで改善します。上記の記事では650をkeepalive_timeoutにセットしています。
この設定を反映させた所、502エラーは出なくなりました。
4.HTTP(S) ロードバランサーのヘッダーを利用し特定のリクエストの処理をトレースする
特定のリクエストの処理をトレースする際に、nginxを利用している場合はngx_txidモジュールを使用してuuidをヘッダーに付与してupstreamにリクエストを送る方法とログに出力する方法があります。
しかし、HTTP(S) ロードバランサーを使用している場合は受けたリクエストに対して「X-Cloud-Trace-Context」というヘッダーを付与してバックエンドサーバーにリクエストを送ります。
このヘッダーの値はリクエストごとに違い、リクエストを一意に識別できる値です。なので、このヘッダーの値をログに出力しておくことで特定のリクエストの処理をトレースすることができます。
ちょっと別件ですが、Stackdriver Loggingにログを全て出力している場合、フィルタクエリで「X-Cloud-Trace-Context」の値を指定することでリクエストのログを表示することができ、とても便利です!!
5.HTTP(S) ロードバランサーを経由してくるリクエストのIP制限
HTTP(S) ロードバランサーを経由してくるリクエストはリモートのIPアドレスがHTTP(S) ロードバランサーに割り当てられているIPアドレスになります。なので、ファイアーウォール ルールで制限をかけたとしてもヘルスチェックのIPアドレスの範囲を許可している場合は全てのリクエストが許可されるようになってしまいます。よって、VM側でIP制限の処理をする必要があります。
クライアントのIPを知る手段ですが、HTTP(S) ロードバランサーは「X-Forwarded-For」というヘッダーを付与します。このヘッダーの値にクライアントのIPを含んでいるため、こちらのヘッダーを活用します。nginxでの例ですが以下のような設定を行います。

「set_real_ip_from」にHTTP(S) ロードバランサーに割り当てられているIPアドレスを設定します。こうすることで、allow・denyディレクティブでアクセス制御ができるようになります。
最後に
今回の移設後、処理時間が1秒以上かかるリクエストが10分の1程度に減り、インフラのコストも移設前に比べると随分と抑えることができました。また、コードでの構成管理を行ったことでレビューがしやすくなり、構築の作業工数もグッと減らすことができました。他にもBigQueryへログを流しているので集計してGoogle Data Studioなどで可視化などを少しずつでも進めていきたいと思います。
今回の移設作業はグリフォンのインフラにとってはただの移設作業ではなく、様々なものを得る絶好の機会でした。そして実際に、ただの移設作業とは思えないほど多くのものを検討し適用して作業を進めていき、本当に多くのものを得ることができました(笑)。
GCPにはコンテナを利用したGKE・GAEやDBのSpanner、データ集計ができるDataflowなど他にも魅力的なサービスがたくさんあり、今後もGCPを積極的に使用していきたいと考えています。

- 徳田 拓也(Takuya Tokuda)東京電機大学卒業後、2016年にインフラエンジニアとしてサイバーエージェントに新卒入社。グリフォンに配属後、新規ブラウザゲームのインフラを構築、後に運用プロジェクトの環境改善を行う。現在、他プラットフォームのインフラをGCPに移設中。気になる技術はコンテナ・kubernetes・GCPなど。Go言語を勉強中