最小限のリスクでGCPに移設するために気を付けたこと。
こんにちは。グレンジでエンジニアをしている稲垣、中陳、村田です。
グレンジで運用しているタイトル「ポコロンダンジョンズ」を弊社プライベートクラウドからGoogle Cloud Platform(以下 GCP)に移設するにあたり、GCP移設チームを組み、2018年7月に移設を実施しました。今回は、移設をするうえで検討したことや、移設後の障害や対策について私たちが実施したことをご紹介させていたただきます。
移設では、特に次の項目に注力しました。
- 構成管理ツール
- 負荷試験
- 移設リハーサル
また、移設後の振り返りでは、
- 移設直後のトラブル
- マルチゾーン対応
- ホストエラーの検知
- DBのバックアップ方式の変更
についてご紹介させていただきます。
移設方針
目的は、「最小限のリスクでプライベートクラウドからGCPに移設をする」としました。そのため、
- できるだけ、既存構成での移設を行う
- ミドルウェアのバージョンは基本的に変更しない
- マネージドサービスの導入は最低限とする
上記の内容を重点におき、移設のスケジューリングを行いました。
当初は、GCP移設とともにマネージドサービスの導入の検討もしましたが、導入することで移設作業やリスクの増加の懸念と、移設後の方が導入しやすいと判断したため、マネージドサービスの導入は最低限としました。一部、Google Cloud Storage (以下、GCS)やStackdriver Loggingを導入しました。
構成管理ツール
移設前の構成管理ツールは、Chefを使用していましたが、GCPの移設に伴い、Ansibleに変更しました。
Ansibleを選択した理由は、
- ローカル環境の構成管理ツールとして使用していた
- 管理対象サーバへのエージェントのソフトウェアのインストールが不要
- GCPモジュールがある
- 定義ファイルがYAML
- モジュールが豊富
- 記述がシンプル
となります。
もともとChefのメンテナンスをきちんとしていなかったこともあり、Chefで管理していた時は、重複コードが散見し、可読性が低くなっていました。
Ansibleで構成管理をするにあたり、ベストプラクティスを参考にしつつ、メンテナンスがしやすいようなディレクトリ構成について事前に話し合いを行い、シンプルなディレクトリ構成にしました。
- Ansibleのディレクトリ構成
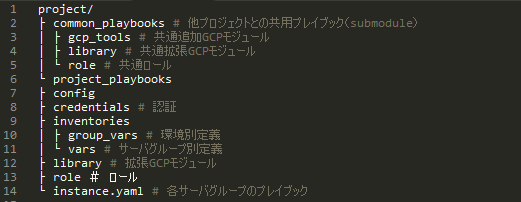
他のサービスに流用できるモジュールやロールはcommon_playbooksでsubmoduleとして管理します。
common_playbooksには、サービス依存する記載はしません。
project_playbooksには、サービス固有のモジュールやロールを管理します。
inventoriesで環境別(本番、ステージング、開発)の情報や各環境のサーバグループ(Web、DB等)の設定を管理します。
以下をAnsibleで管理しています。
- ネットワーク
- サービスアカウント
- GCEインスタンス
- ロードバランサ
- GCS
- Stackdriver Logging
負荷試験
負荷試験目的
プライベートクラウドからGCPに移設後、アプリケーションのレスポンスに劣化しないことを検証。
負荷試験シナリオ
負荷試験シナリオは既存の環境で使用したシナリオを使用し、以下の内容の負荷試験をGCPの環境で実施。
1. 本番のアクセスピーク帯と同様の負荷
2. 本番のアクセスピーク帯の4倍の負荷
GCP環境の負荷試験の結果と、既存環境の解析結果から、リクエストURIごとのレスポンスの比較を行い、集計。
集計内容が以下となります。
集計結果一部抜粋
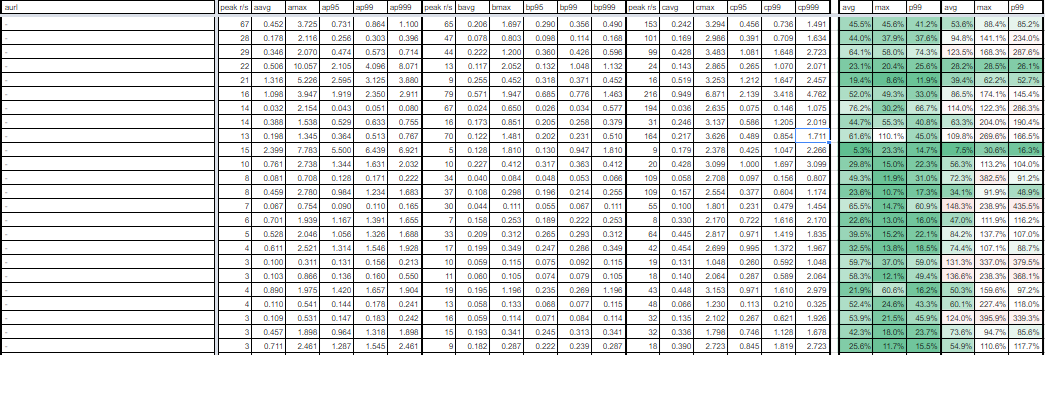
集計した結果、劣化はほとんどせず、既存環境より40%程度のレスポンスの改善が確認できました。
移設リハーサル
移設をするうえで課題となるのは、
- 移設後の無障害
- メンテナンス時間厳守
- 移設による障害への迅速な対応
と考えました。
この課題を解決するため、私たちは移設リハーサル実施しました。
役割分担
移設作業は複数人とし、役割分担を行いました。
作業実施時は必ずダブルチェックで作業を行います。
- ファシリテーター : 進行管理
- 実施者 : 作業実施
- タイムキーパー : 計測・作業確認
- オブザーバー : 作業確認
移設手順書
ホストごとで作業する内容を時系列に並べて作成しました。
本番移設手順書一部抜粋
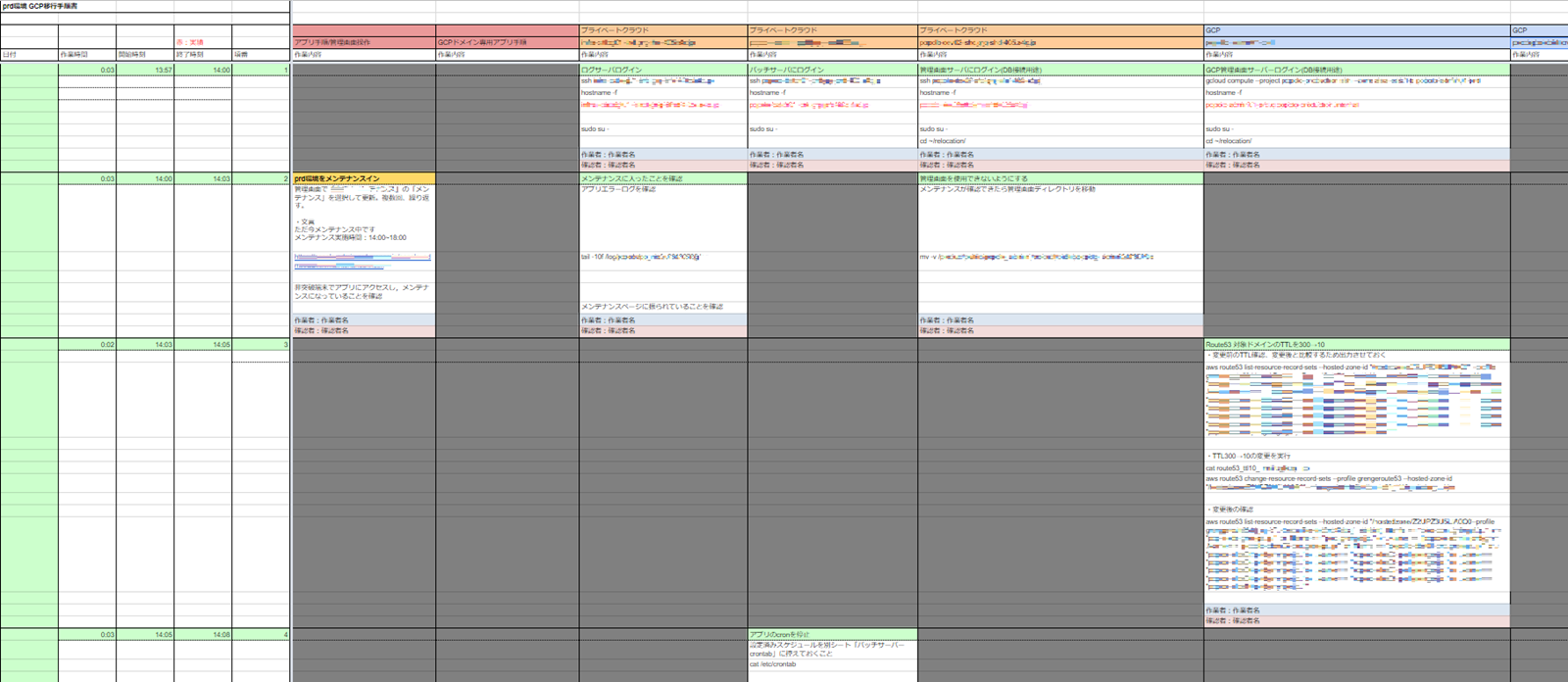
手順書作成者とその手順書に従い移設を行う作業者は異なるようにしました。
コマンド実行などの手順が個人PCの環境に依存するのを避けるためです。
移設リハーサル内容
1. 有識者に移設手順書をレビューしていただき、フィードバックを移設手順書に反映
2. プライベートクラウドに本番環境と同じ構成を最小限の台数で構築。データベースは本番同等のものを用意
3. GCP環境に既存の本番環境と同じ構成を最小限の台数で構築
4. 移設用ドメイン作成
5. 移設手順書に沿って移設作業。各タスクの作業時間計測
6. 作業手順確認ミーティング。時間がかかる作業は自動化やシェルを作成するなどの検討
7. 移設手順書の作業漏れを移設手順書に反映。移設作業に必要な手順、コマンドは全て手順書に記載する
8. 1 ~7の作業を再度実施
この移設リハーサルにはエンジニア以外にも、プランナー、デバッガー、CSとポコロンダンジョンズのチームメンバーを巻き込んで行いました。
移設スケジュールが逼迫する中、それでも時間をいただき、2度のリハーサルを実施できたことで、移設作業は大きな障害なく、メンテナンス時間も厳守することができました。
移設直後のトラブル
一部のAndroid端末でWebSocket通信ができない
移設直後に一部のAndroid端末で共闘クエストができないということがお問い合わせで発覚。
※共闘クエストは自分だけではなく、他のプレイヤーと協力して最大4人で同じクエストに挑戦することができる機能です。
GCP移設後は、HTTP(S)ロードバランサのターゲットプロキシでSSL証明書管理するようにしたため、AndroidのOSバージョンが4.0.4以下の端末のWebSocket通信で使用する暗号スイートがGCPで対応していない暗号スイートだったため、通信エラーとなった。
根本原因の解決に時間がかかると判断したため、別途TCPロードバランサ、インスタンスグループを作成し、インスタンスグループで管理するNodeでSSL証明書管理するようにし、サーバ処理でAndroidのOSバージョンが4.0.4以下の端末の場合に新規で作成したTCPロードバランサに振り分ける処理に修正。
日付ごとで集約しているログに異なる日付のログが混在し、KPIの集計が正常に行われなかった
google-fluentdは、Stackdriver Loggingエージェントで、Stackdriver Loggingにログをストリーミングでき、また、fluentdログデータコレクタに変更を加えたもので、既存の環境で使用しているfluentdの設定を引き継ぐことが容易であるため、ログ収集ツールをfluentdからgoogle-fluentdに変更しました。
既存の設定のままgoogle-fluentdで
- ログ収集サーバにログの種類別に収集できている
- 各ログの種類別に日付ごとに出力される
- ログの内容は正常か
と確認を行っていたのですが、日付の切り替わりの確認が漏れていました。
結果、プラグインの設定に不備があり、UTCで処理され、9時間の時間のズレが生じて日付ごとのファイルに収集されていました。
一部割愛していますが、修正内容は以下となります。
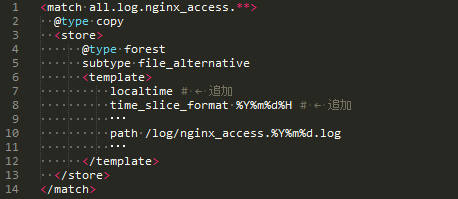
修正後、データ不備を修正し、KPIの再集計を行いました。
マルチゾーン対応
移設前の既存環境では、データベースの冗長化の方式はアクティブ・スタンバイ構成、マスター・スレーブ構成となっており、MHAで高可用性を実現させていました。GCP移設後も同様の構成です。
GCEインスタンス
- master: アクティブ(マスター)
- standby: スタンバイ
- slave: スレーブ
- mha: MHAマネージャ
移設当時は、全てのインスタンスをシングルゾーンで管理していました。
Google Compute Engineのドキュメントでダウンタイムの定義のひとつにマルチゾーン対応したうえで、どのゾーンの代替インスタンスも起動できない状態と記載があり、それを怠っていました。
移設後、複数のデータベースでホストエラーが発生し、フェイルオーバーやレプリケーションが切れるという現象が複数台で起こりました。この現象で、サービスの一時的な接続障害が発生しました。(ホストエラーは仮想マシンをホストしている物理マシンがクラッシュするようなハードウェアまたはソフトウェアの問題が発生したことを意味する)
障害回避、影響範囲の最小化を図るため、
1. ハードウェアに起因するのであれば、異なるゾーンで同時に起こらないはずなので、
ゾーン間のレイテンシが問題にならない程度の場合、データベースおよびmhaのマルチゾーン対応を検討
2. 同一ゾーンで同じ筐体に乗らないような設定がないか
3. 改めてマネージドサービスの検討
上記の内容でGCPカスタマーエンジニアの方とのミーティングを行いました。
2.の内容に関しては、リージョンによりますが、インスタンス別にCPUのバージョンを変更すれば、同じ筐体に乗らないことをご教示いただけたのですが、サーバグループでCPUを変更し、性能差が出ることに懸念がありました。
3.に関しては、導入コストが高いので、今回は見送りました。
結果、1.の内容の検討をはじめました。
まず、ゾーン間のレイテンシを計測しました。
計測結果からゾーン間のレイテンシがほとんどないことが確認できました。ゾーン分散に関しては、masterとstandbyにmhaのどれかに障害が起きてもサービス影響がないようにこれらを同一ゾーンに配置しない構成としました。また、サービスのメンテナンスを行わないで構成を変更するため、masterは現在ゾーン(ゾーンb)とし、以下の内容で構成を変更しました。
- master: ゾーンb
- mha: 偶数機がゾーンa、奇数機がゾーンc
- standby: 奇数機がゾーンa、偶数機がゾーンc
- slave: 偶数機がゾーンa、奇数機がゾーンc
これらの構成変更することで偶発的なホストエラーからのサービス影響を防いでいます。
ホストエラーの検知
ホストエラーによる障害が起きた場合、仮想マシンの障害ですので、インスタンスが停止したり、データベースのレプリケーション障害が発生したりと多岐に渡ります。
ホストエラー起因の障害の場合、gcloudコマンドの”gcloud compute operations list”で確認が可能ですが、過去1か月程度くらいまでしか調査ができません。また、アラートの種別にもよりますが、毎回gcloudコマンドを確認するのも手間です。そのため、ホストエラーが発生した場合にChatWork投稿とDatadogに通知するようにしました。
1.Stackdriver Loggingのエクスポートを利用
ホストエラーが起きた場合に、さきほどのgcloudコマンドと、Stackdriver Loggingでの確認ができます。
Stackdriver Loggingのシンクを作成し、エクスポートを行います。
シンクのフィルタには、以下を設定し、

シンクサービスには『Cloud Pub/Sub』を指定し、トピックを作成します。
2. Cloud Functionsをトリガーする
エクスポートで作成したトピックにパブリッシュされたメッセージからCloud Functionsをトリガーするため、トリガーされる、Cloud Functionsを作成します。Cloud FunctionsからChatWork投稿とDatadogにメトリックを送信します。ChatWork投稿でChatWorkAPI、Datadogでdogapiを利用しました。
作成したCloud Functionsをでデプロイします。
デプロイのオプションで、
–trigger-event: google.pubsub.topic.publish
–trigger-resource: エクスポート先のトピック
を指定しています。
これで、ホストエラーが発生した場合にChatWorkとDatadogに自動で通知されます。
DBのバックアップ方式の変更
既存環境では、XtraBackupを利用してデータベースのバックアップを行っておりましたが、(容量が膨大なため)バックアップに数時間かかることもあり、どうにかできないか検討しました。そこで、スナップショットを利用し、効率的なバックアップ・リストアを行うように変更しました。
主なスナップショットの特徴は以下になります。
- 高速に取得可能
- 差分取得
- 世代管理
- グローバルで利用可能
差分取得により、大量データでもバックアップが高速に行え、さらに、コストが最小限で済みます。
master⇔slaveでレプリケーションを行っており、定期的にslaveのバックアップを取るように考えました。
最初はレプリケーションをしている状態でスナップショットを作成し、リストアの検証をしてみました。結果、レプリケーション再開時にDuplicateエラーで失敗。
運用しているバージョンの場合、レプリケーションをしながらのバックアップは、master.info/relay-log.infoがflushされていないため、レプリケーション再開時に再開位置が巻き戻り、Duplicateエラーとなりました。次に、レプリケーションを止めて、スナップショットを作成する検証を行いました。
スナップショット作成手順
1. レプリケーション停止
2. 内部キャッシュのクリア
3. メモリの内容をディスクに書き込む
4. スナップショット作成
5. レプリケーションを再開
リストア手順
1. リストア対象のインスタンスを停止
2. 停止したインスタンスのディスクを外し、ディスクの削除
3. スナップショットからディスクを作成し、インスタンスの追加
4. インスタンスを起動
この手順で作成したスナップショットで正常にリストアできることが確認できました。
バックアップ方式をスナップショットに変更したことにより、バックアップ容量の削減、バックアップ・リストア時間効率向上につながりました。(バックアップで10~20分、リストアで20~30分)
リストアはgcloudコマンドで実行することができ、今後は自動化を検討しています。
スナップショットによるバックアップが短時間でできるようになったため、リストアがしやすいように1日に数回のバックアップを作成していますが、スナップショット数の上限に達してしまうという懸念がありますので、定期的なスナップショットの自動削除を検討しています。
今後
今回の移設は、GCPへ移設ということが主目的でしたので、既存の環境の構成を踏襲した構成で移設を行いました。
それでも、サービスのパフォーマンスの改善と運用フローが改善がされました。
現在はGCPの一部のマネージドサービスの利用に留めていますが、ほかにも
と魅力なマネージドサービスが多くあります。
今後は、積極的にGCPのサービスを検証、利用し、運用改善、運用コスト改善をしていきたいと考えています。
参考
・Google Compute Engine サービスレベル契約(SLA)
・Google Compute Engine のよくある質問

- 稲垣 悟(Satoru Inagaki)2012年にサイバーエージェントグループのモバイルサービス開発系子会社に入社。モバイルゲームの新規開発・運用に携わる。2014年にグレンジに異動。「ポコロンダンジョンズ」をプライベートクラウドからGCPに移設。現在は、新規ゲームのインフラを構築中。GCPのマネージドサービス導入に注力。

- 中陳 里志(Satoshi Nakajin)2011年にサイバーエージェントグループのモバイルサービス開発系子会社に入社。いくつものスマートフォンゲームの開発・運用に携わる。2014年、グレンジに異動。サーバーサイドエンジニアとして、「ポコロンダンジョンズ」の開発・運用に携わる。現在は、新規ゲームの開発を担当。

- 村田 浩士(Hiroshi Murata)2012年にグレンジ入社後、サーバーサイドエンジニアとして新規ゲームの開発・運用に従事。2015年からサイバーエージェントのゲーム・エンターテイメント事業(SGE)のいくつもの新規ゲーム開発に携わる。現在はグレンジの新規ゲームの技術検証や「ポコロンダンジョンズ」の運用改善を担当。